谈谈排序模型的 negative sampling 问题。取不好题目TAT…
之前在用 Dual Encoder 这类 ranking model 时,发现在一些问题上尽管大方向上匹配的很好,比如人名问题答的都是人名,歌曲问题回答的都是歌曲名,但是具体到再细的粒度就完全匹配不上了。明明知道这显然是 negative sampling 的问题,却一直没找到好的解决方案,毕竟 google 一下 negative sampling 发现前 5 页都是在讲 word2vec……
感觉这应该算是 ranking 模型中一个非常实际也非常常见的问题。在训练的时候,我们一般不会在整个模板库上进行排序,这样效率太低也容易错,而是会做随机负采样,比如随机选 19 个负样本,和正确答案一起作为候选答案(ranking size=20)。但在实际应用中,又往往需要对整个模板库排序,或者至少要用别的方法召回一批样本(包含正确答案)再进行预测。这样一来,如果训练时随机的负样本太弱太简单(和正确答案差异性很大),而在预测时候选答案又太难太挑战(和正确答案很相似),效果当然就不好了。
当时自己折腾的时候尝试过很多方法,比如扩大 ranking size,多采样负样本,发现收益并不大,也试过先召回一部分和答案相似的样本,再做 reranking,或者在 DE 前或者后加别的 ranking 来进一步缩小范围,也是收效甚微,另外资源限制很多实验都没跑的很完美就暂时把这个问题放下了。直到最近看到了 tambetm/allenAI 这个,发现这个小哥哥用了一种不错的 negative sampling 的方法,看上去很有道理的样子,借鉴的还是 15 年的工作,哎都怪我读书少之前木有接触过现在才发现(╥﹏╥)
简单来说就是选择难度适当的错误回复(semi-hard negative samples)作为负样本,这个 idea 来自 15年 FaceNet 那篇文章,过去瞅了瞅,就从 FaceNet 讲起吧。FaceNet 最大特点应该就是提出了 Triplet Loss 的概念,也就是在向量空间内,希望保证单个个体的图像 $x^a_i (anchor)$和该个体的所有其它图像 $x^p_i(positive)$ 之间的特征距离尽可能的小,而与其它个体的图像 $x^n_i(negitive)$ 之间的特征距离要尽可能的大(差不多就是 LDA 的思路嘛,最大化类间距离最小化类内距离)。
Here we want to ensure that an image $x^a_i (anchor)$ of a specific person is closer to all other images $x^p_i(positive)$ of the same person than it is to any image $x^n_i(negitive)$ of any other person.
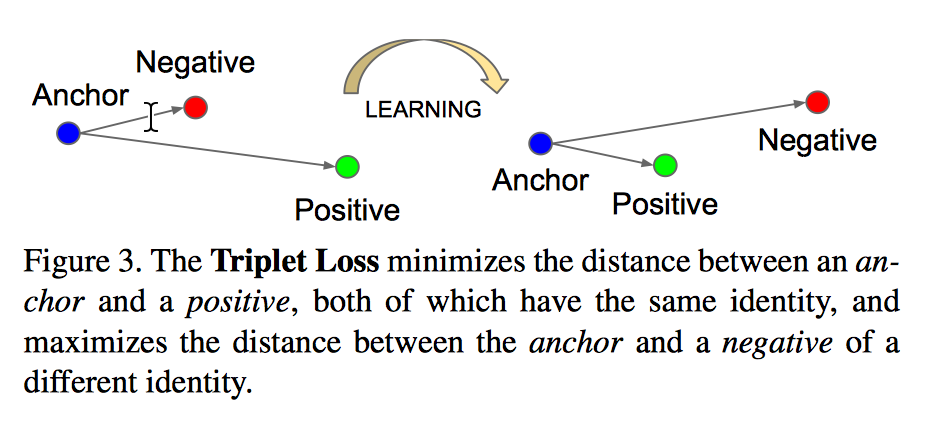
然后 loss 的设定就是说通过学习,使得类间距离大于类内距离,$\alpha$ 作为 positive/negtive 边界,是一个常量。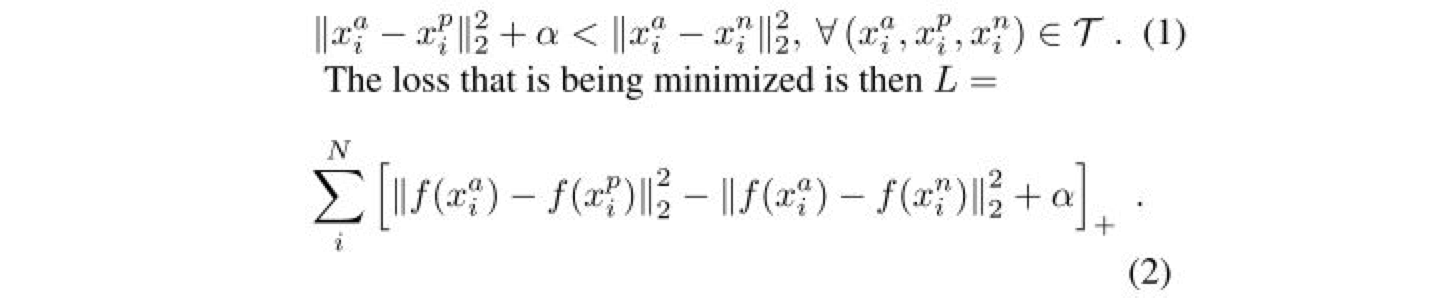
Triplets 显然不能穷举,这样一来筛选 triplets 就很重要,为了最快收敛考虑当然是首选最难区分的图像对了,也就是 hard positive ($argmax_{x^p_i}||f(x^a_i)-f(x^p_i)||^2_2$) 和 hard negative ($argmin_{x^n_i}||f(x^a_i)-f(x^n_i)||^2_2$)。举个例子,如果整体样本集是 1000 个人每个人 40 张图片,给定某个人的图片来选 triple,那么自然选这个人另外 39 张图片中和它最不相似的图片作为 hard positive,以及剩下 40*999 张图片中和它最相似的图片作为 hard negative。
挑选 hard positive 和 hard negative 有 offline (generate triplets every n steps) 和 online (select triplets within a mini-batch) 方法。论文重点聚焦在了 online 方法,在一个大的 mini-batch (1800 个样本)中选择所有的 anchor-positive pairs,同时,来选择一定的 hard anchor-negative pairs,但选择 hardest negatives 在实际当中容易导致在训练最开始的时候就陷入局部最优,所以实际会选择 semi-hard negatives,使挑选样本满足下面的式子: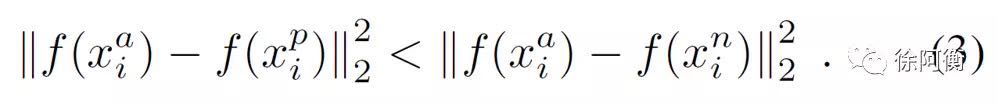
这个约束就是 semi-hard。再回过头来看开始的 repo,模型用 RNN 对 question 和 answer 进行编码,然后用 cosine ranking loss,也就是让 question 和 right answer 的 cosine 距离小于 question 和 wrong answer 的 cosine 距离。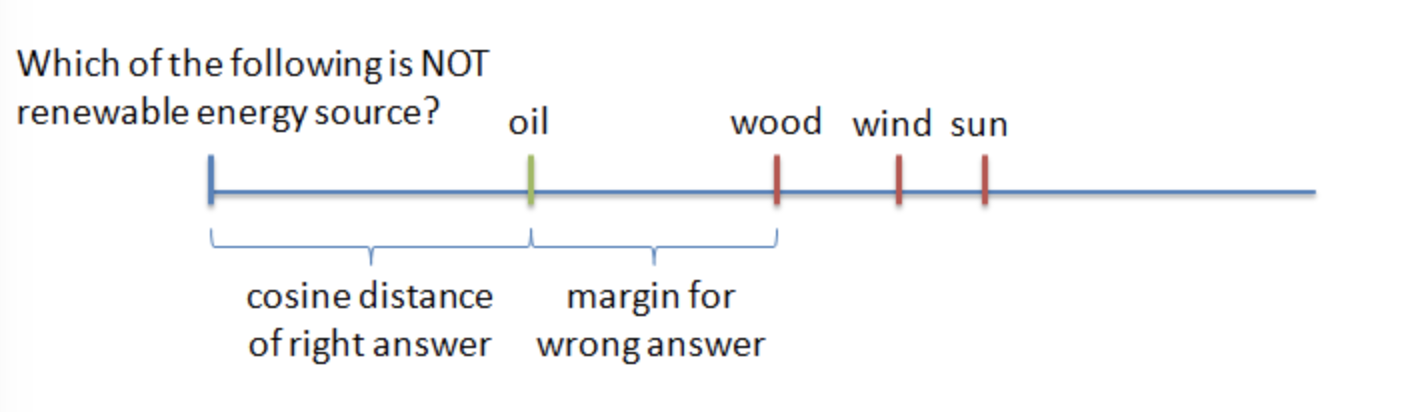
wrong answer 采用 neagtive sampling,选择难度适当的 wrong answer,或者说选择当前模型能正确分类但是没那么 confident 的 wrong answer。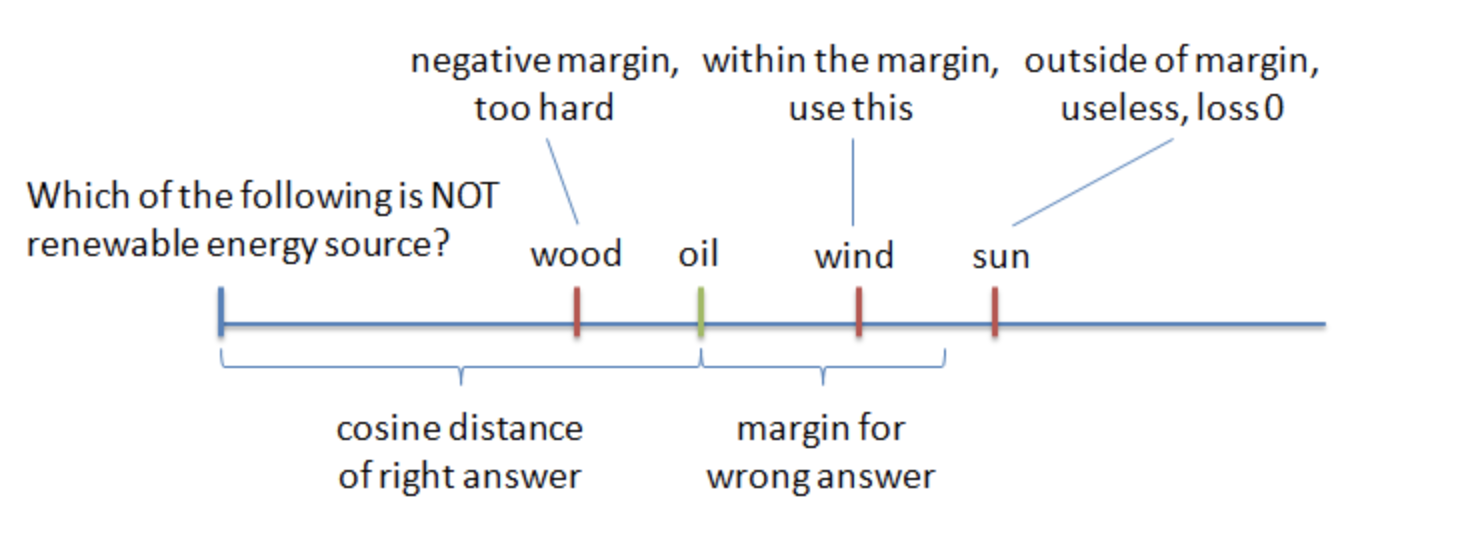
他们是发现 too hard answer 会使模型难以收敛,而实验表明:
Semi-hard negative samples, which are further than the right answer, but still within the margin - works best
参考连接:
谷歌人脸识别系统FaceNet解析
FaceNet: A Unified Embedding for Face Recognition and Clustering

